こんにちは。プロダクト開発部の新田です。
AGRI SMILEで、複数プロダクトをフロントエンド・バックエンドに亘って開発する業務をしています。
AGRI SMILEでのHerokuのユースケース
AGRI SMILEでは、オンラインで学術集会を開催できるプラットフォーム、ONLINE CONFを提供しています。
このシステムはHerokuを利用してホスティングされています。
なぜAWSやGCP等のクラウドインフラでなくPaaSであるHerokuを利用しているかというと、WEBアプリケーションエンジニアであっても容易にインフラをコントロールできるのが一つの理由ですが、なにより学術集会の性質との親和性が高いからです。
具体的には、学術集会はシステムの観点から見ると、
- 半年から1年程度の間、準備のために定常的に低頻度のアクセスが発生する
- 開催当日は一気に同時アクセス数がスパイクする
- スパイクのタイミングは予測でき、その際の負荷の上限も(参加者数などからある程度)事前に予測できる
- イベント(や後日配信等)が終了すると、システムが利用されなくなる
という特性があります。
Herokuは、WebUIまたはコマンドラインで簡単に立ち上げ・スケールさせ・クローズさせることができ、学術集会のこれらの性質とかなりマッチしていると考えています。
また別プロダクトでは Salesforceとのデータ連携に Heroku Connectを使っているところもあり、AGRI SMILEはHerokuをよく使っています。
そういう背景もあって、今回EC2やECSでなく踏み台サーバーとしてHerokuを使う話について書いてみます。
この記事で説明することと背景
Heroku の One-off dyno を使って us-east にある RDS から速やかにダンプを取得し、それを Tailscale を通じてローカルに転送する手順を説明します。
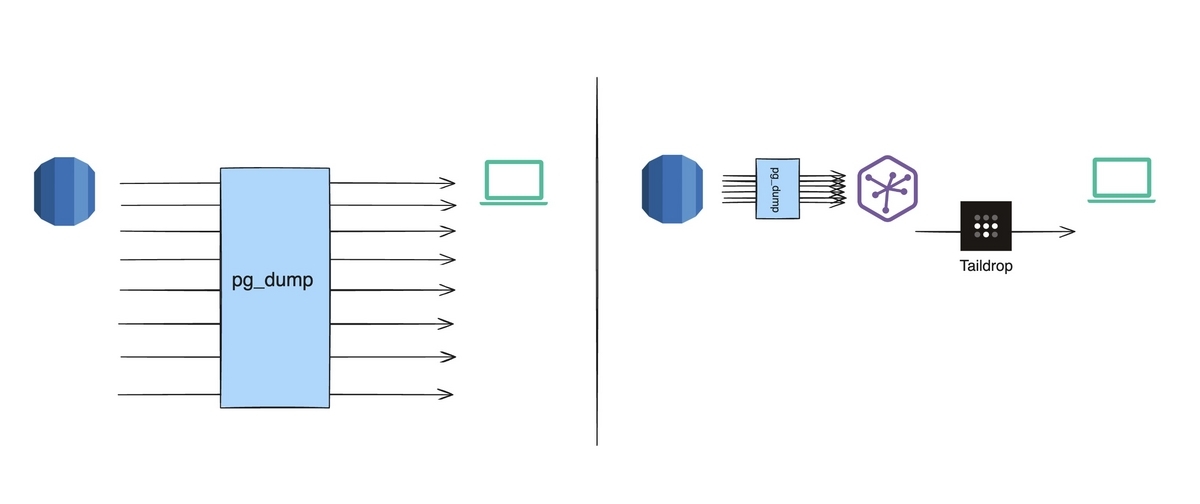
インフラとして完全にHerokuを利用していれば heroku pg:backups:download -a <app_name> で Heroku Postgres からダンプファイルを得られますが、
弊社では一部でAWS RDSやAurora を利用しており、この便利機能が使えません。
そこで、通常はローカルにダンプファイルが欲しい場合、
$ pg_dump -d postgres://user:pass@xxx.com:5432/xx -F custom -f latest.dump -v
を実行して直接DBからダンプを取得することがあります。
ただ、(Herokuはサーバーの物理的な所在地がアメリカ、というか us-east にある関係で)AWSのDBもアメリカのリージョンのものを調達しています。
pg_dump は頻繁に通信を行うため、通信距離が大きいとバックアップの取得時間も長くなってしまいます。
ステージング用のディスク使用量数MB程度の小さなDBを使って実際に計測してみると、Heroku One-off dynoでバックアップを取得すると1秒、手元のマシンでバックアップを取得すると1分40秒かかりました。
(time コマンドを使って数回計測。 手元のマシンはM2 MBP, Herokuのdynoはstandard 1X で、マシン性能の差ではないことを念のため付記しておきます。)
より大きなDBではこの差が更に大きくなり、Heroku dyno上のダンプファイルをローカルに転送する時間を考えてもお釣りがくるようになります。
しかしHeroku dynoは通常scpできませんから、dyno上のファイルをローカルに持ってくるには工夫が必要です。
方法はいくつか考えられ、 file.ioやtransfer.shを利用して一度外部サーバーにアップロードしてダウンロードするのが最も手軽ですがDBのダンプを他所に預けるのはセキュリティ上の問題があり、S3にアップロードするのは面倒です。
そこで、Tailscaleをインストールした踏み台dynoをHerokuに用意しておいて、そこでダンプを取ってローカルとTailscale経由で通信してファイルを持ってくる方法を今回紹介します。
TailscaleがインストールされたHerokuアプリケーションを用意する
アプリケーションのセットアップ
適当な Herokuアプリケーションを新規に登録します。
Heroku には環境一式をインストールできるbuildpackという便利な仕組みがあり、 有志がTailscaleが使えるbuildpackを作って提供してくれているのでこちらを利用します。
$ heroku buildpacks:set https://github.com/aspiredu/heroku-tailscale-buildpack -a <app_name>
buildpack は次回デプロイ時に反映されるので、適当なProcfileを作ってgitリポジトリを作り、アプリケーションとしてデプロイします。
# Procfile web: echo a
今回はOne-off dynoを利用したいだけで、webサーバーとしての働きを期待しないのでProcfileは適当でよいです。
また、リポジトリの中身もProcfile以外なにも置かなくて良いです。
認証キーの設定
先程のbuildpack は環境変数 TAILSCALE_AUTH_KEY にtailscaleの認証キーを要求します。
認証キーの取得方法はこちらのStep1の記載の通りです。
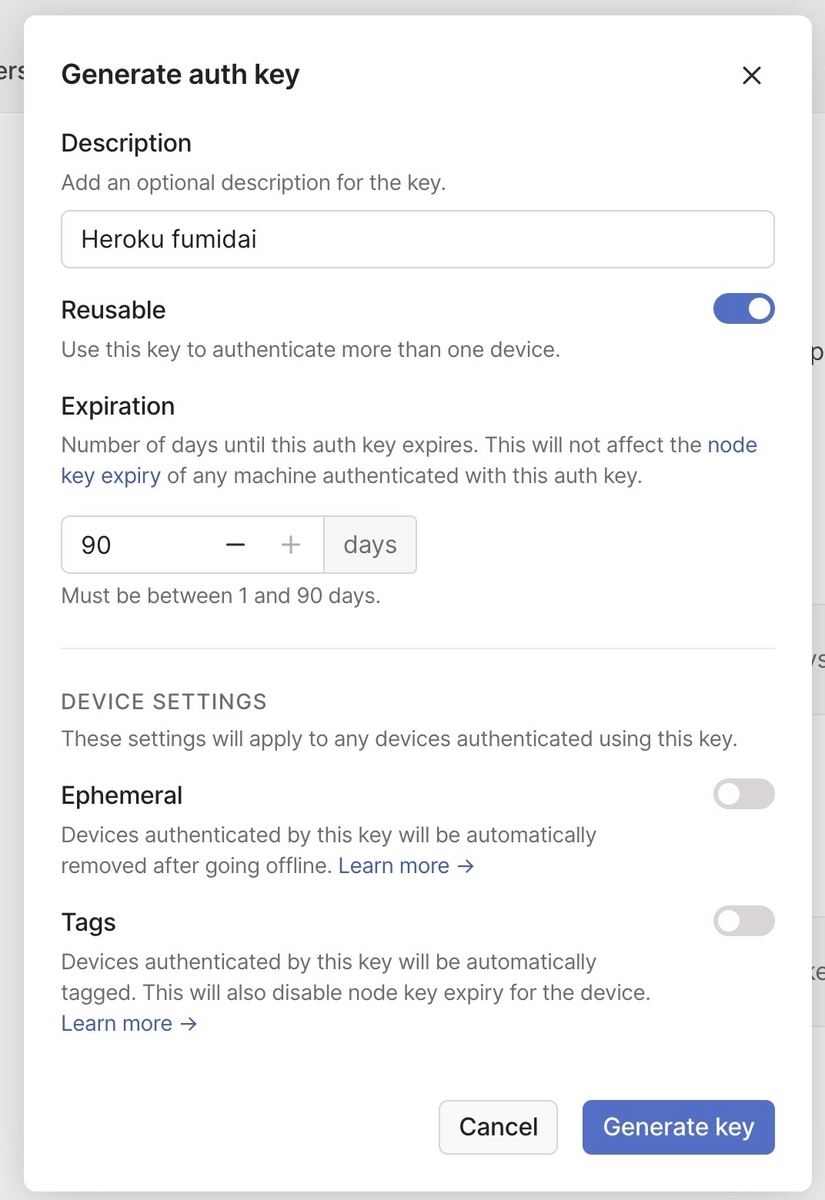
キーが取得できたら、Heroku アプリケーションの環境変数にセットします。 heroku config:set TAILSCALE_AUTH_KEY=<キー> -a <app_name>
反映を待って heroku run /bin/bash -a <app_name> で正しく設定できてそうかチェックします。
-----> Skipping Tailscale
と出たら設定が完了していません。
-----> Starting Tailscale
に続いて標準出力がやかましくなったら設定完了です。
このとき、Tailscaleのダッシュボード上でもオンラインのデバイスが増えていることが確認できます。
dynoからローカルにファイルを送る
pg_dump 等で目的のファイルをdyno上に生成したら、Taildrop という機能でリモートからローカルにファイルを送ります。
$ tailscale file cp ./latest.dump <ローカルマシン名>:
すると、(私の環境では)~/Downloads ディレクトリに latest.dump が送り込まれてきます。
まとめ
- pg_dump は通信速度の影響を強く受けるらしい
- Herokuは一時的な踏み台サーバーとしてとても便利
- Tailscale はHerokuのdynoと通信するのにも使えて便利だしセキュア